Arkitekturoversikt
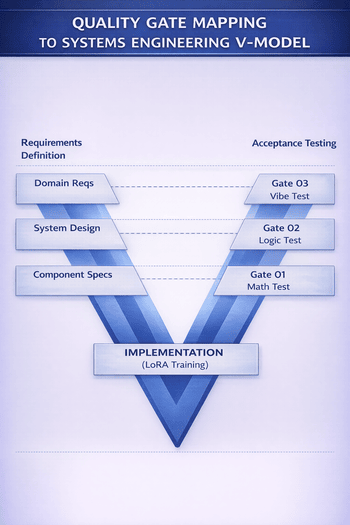
Systemarkitekturen følger et trinnvis destillasjonspipeline-mønster, der hver komponent er frakoblet og uavhengig verifiserbar — et sentralt systems engineering-prinsipp som muliggjør inkrementell validering. Arkitekturen består av fire primære delsystemer:
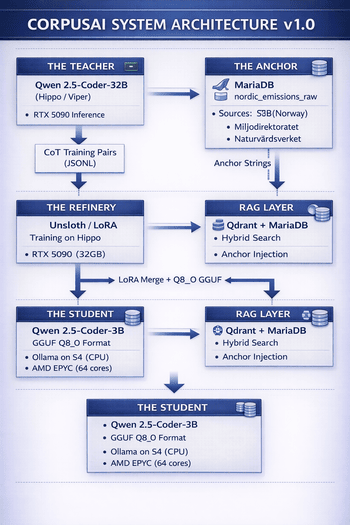
Lærermodellen med 32 milliarder parametere kjører på Hippo/Viper GPU-klusteret (RTX 5090). Den prosesserer ankerdata og genererer Chain-of-Thought (CoT) resonnementpar som danner treningskorpuset for elevmodellen. Lærerens rolle er å demonstrere hvordan man tenker om utslippsdata — ikke bare hva svaret er.
Elevmodellen med 3 milliarder parametere er utrullingsmålet. Trent via LoRA-finjustering på lærerens destillerte utdata og forankret i verifisert statistikk, oppnår den nær lærernivå nøyaktighet med 10× raskere inferenshastighet. Kvantisert til Q8_0 GGUF for ren CPU-utrulling på S4-serveren (AMD EPYC).
Ankerlaget er systemets «Ground Truth»-garanti. Råutslippsdata fra SSB (Statistisk sentralbyrå), Miljødirektoratet og Naturvårdsverket lagres i en normalisert MariaDB-tabell og transformeres til faktaark på naturlig språk under trening. Dette sikrer null hallusinasjoner på faktaspørsmål.
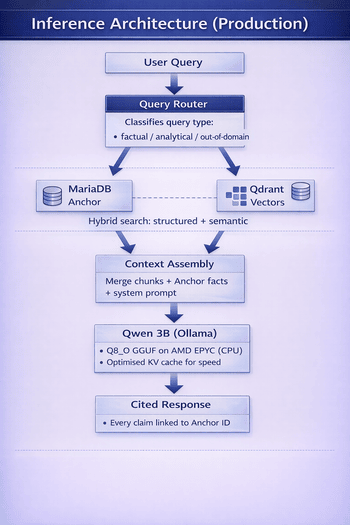
Ved inferenstidspunktet utfører et Retrieval-Augmented Generation (RAG)-lag hybridsøk på tvers av Qdrant-vektorembeddinger og MariaDB-strukturerte data. Hentede tekstbiter og ankerdatafakta injiseres i promptkonteksten, slik at 3B-eleven kan gi siterte, verifiserbare svar.